ENG - OSINT Techniques | How to find impersonate website

Overview
During my investigation, I’ve encountered several impersonation websites—such as fake Facebook pages and fraudulent login panels—commonly used in phishing, fraud, or scam campaigns.
My role involves tracking these websites to report them to phishing repositories or identifying the potential owners behind these domains.
Today, I’ll walk you through some of the Tactics, Techniques, and Procedures (TTPs) I use in my investigations.
Most of these TTPs focus on identifying Unique Identifier Labels (UILs)—distinct characteristics of a website or domain. These could include specific wording, HTML content, snippets of JavaScript code, overlaps in WHOIS historical data, or any other unique element that can help pivot to related information.
Instead of simply listing tools and theoretical examples, we’ll dive into a case study. Remember, OSINT is more about mindset than tools.
General Knowledge | Finding the seed information | Phishing
I’ve often repeated this quote: Master yourself, master the enemy.
Let’s begin by examining the original Telegram web page. Understanding the legitimate site first will help us identify what makes it authentic.
How do we determine if a website is legitimate?
- Domain and IP address
- HTML & Javascript content
- Hmm… what else? For now, let’s focus on the domain/IP address and the HTML content.
Next, let’s explore how attackers distribute these impersonation websites:
- Email phishing
- Direct message phishing
- SMS phishing
- Google, YouTube, Facebook ads—or online ads in general
These methods are typically linked to what’s known as phishing kits.
To effectively track these types of threats, we need to identify where information related to them is stored.
Study Case: Telegram Login Panel
Requirement or Investigation Objective
- Find any Impersonate Telegram Login Page
- Check if those website belong to a mass phishing campain or not
- Find the person behind the impersonate website if possible
Collection
Alright, let’s start tracking the Telegram login panel. But there’s a challenge—you could scan the entire internet, store all that data, and query it to find HTML content and domains that differ from the original site but still display the logo or other familiar elements. However, that approach would be incredibly time-consuming.
Instead, I’ll use some free internet scanning tools. (Though, one day, I might build my own database for this—because I love creating things.)
- URLScan.io
- Censys
- Shodan
- Hunt.io
- Fofa
- Virustotal
- Hybrid Analysis
- VirusTotal (if you have a premium account)
- AnyRun
- Whois Database
- URLHaus
- Python
- Google Dorking
- PhishTank
- PhishStat
- StalkPhish OSS
Notable Mention: Validin
I know, I know—there are a ton of tools out there. But remember, the second step in Cyber Threat Intelligence (CTI) or any intelligence process is COLLECTION (the first is thr REQUIREMENT). We need to gather as much information as possible, and these tools serve as our sources for that data. While they come with some limitations, that’s perfectly fine.
Now that we’ve got a solid set of data sources to work with, let’s dive in.
We’ll start by examining the legitimate Telegram login page to understand what normal looks like. This will help us pivot and refine our searches effectively.
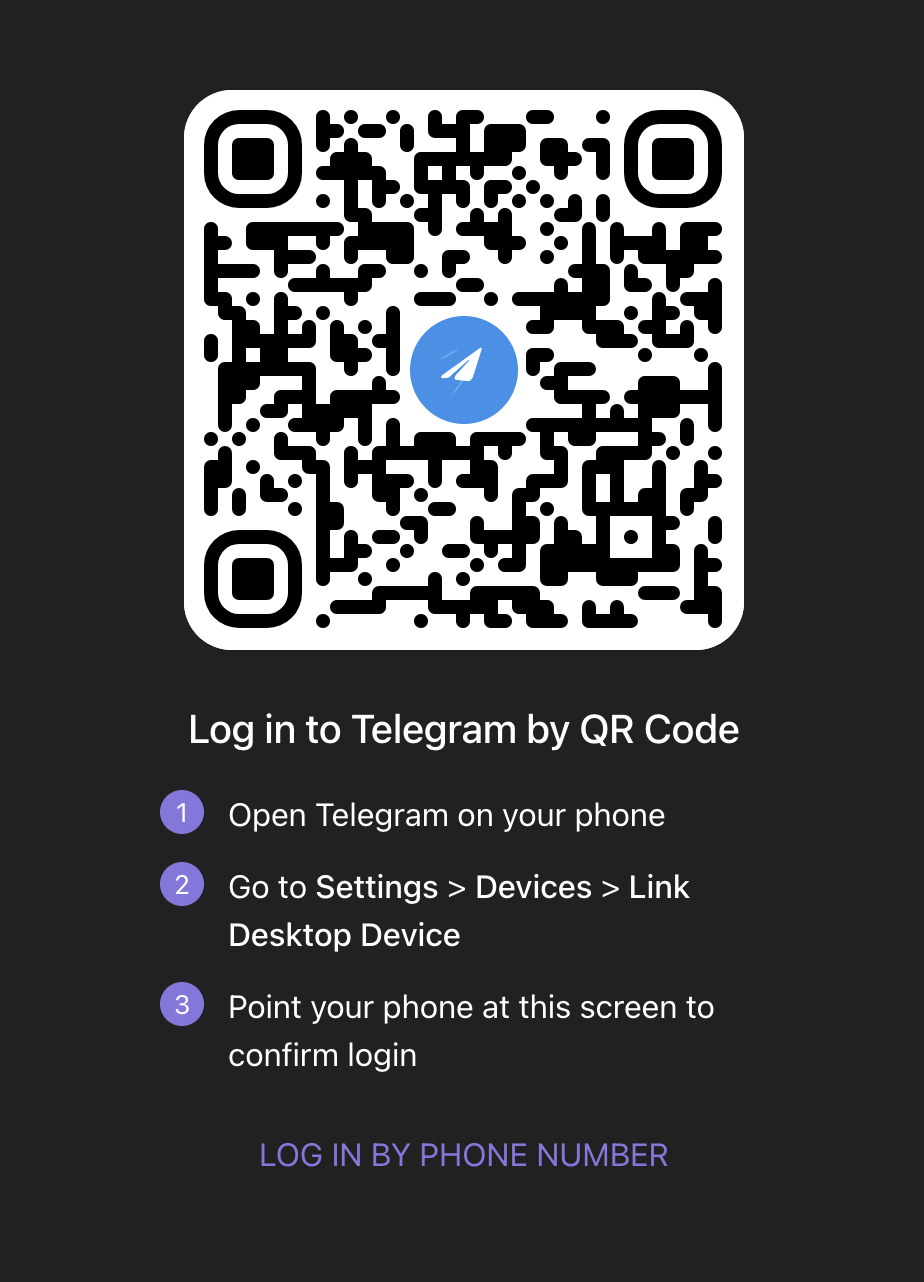
Telegram Legit QR Code Login
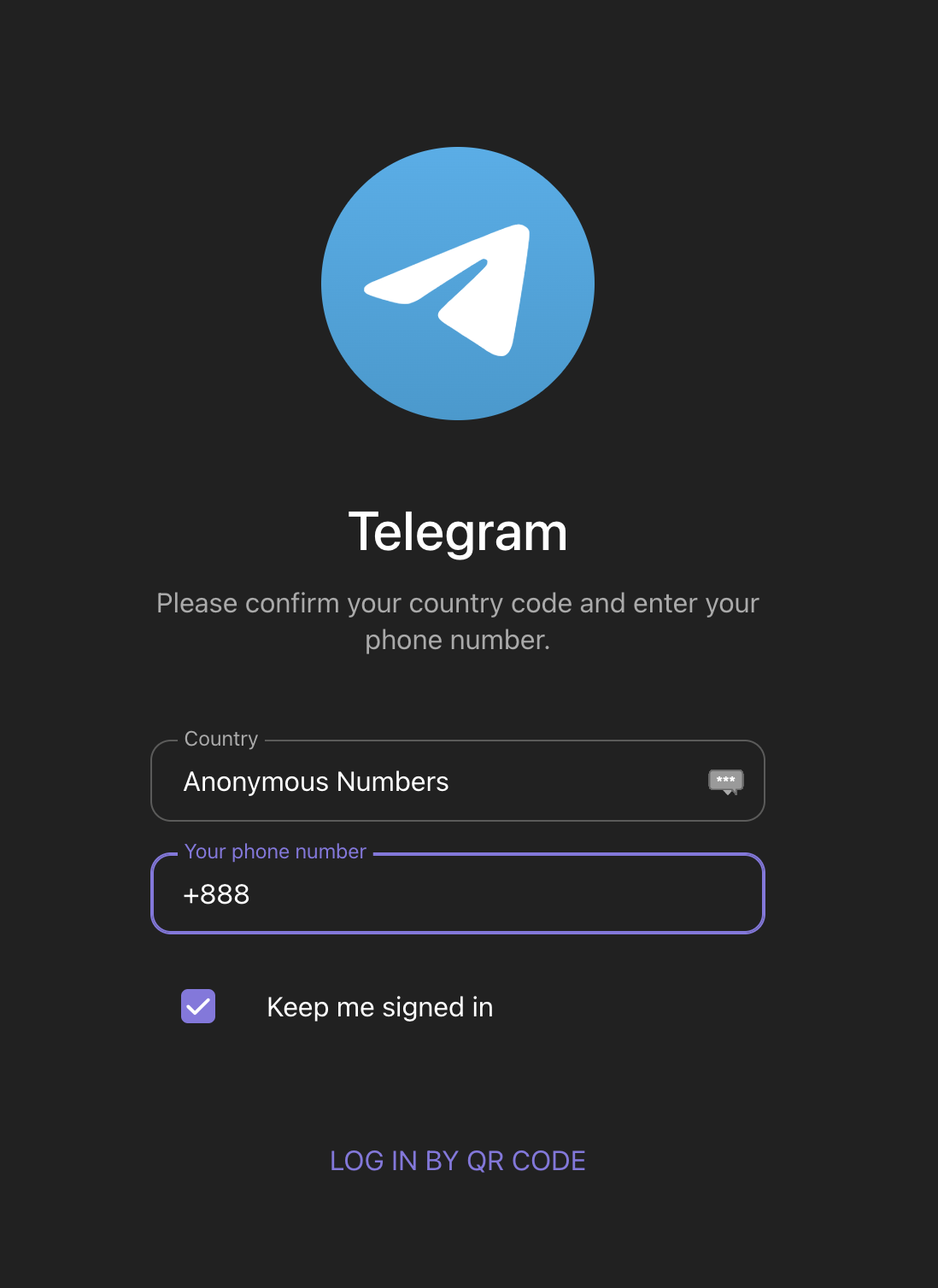
Telegram Phone Number Login
Telegram Title
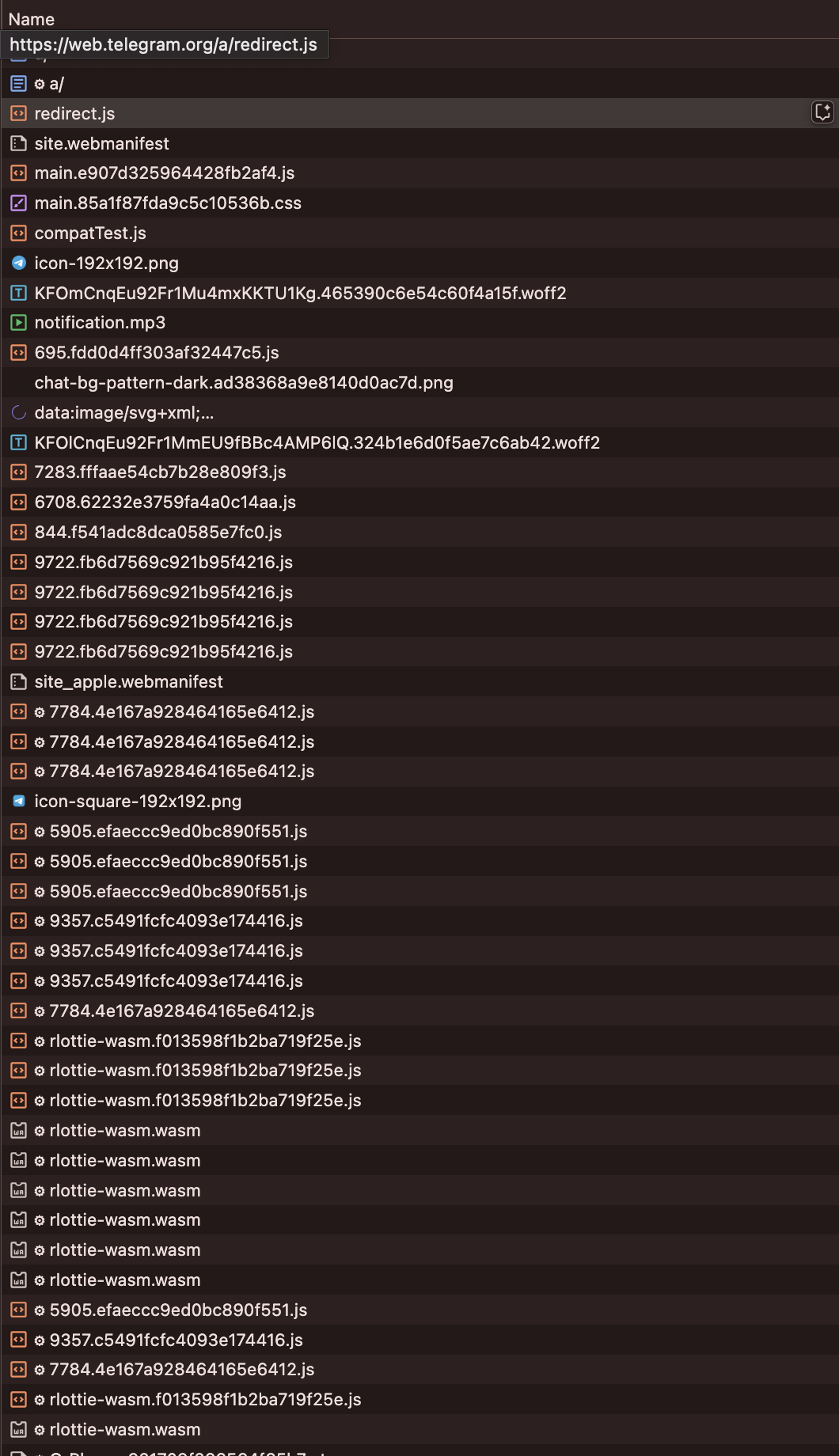
Javascript & HTML & CSS content loaded
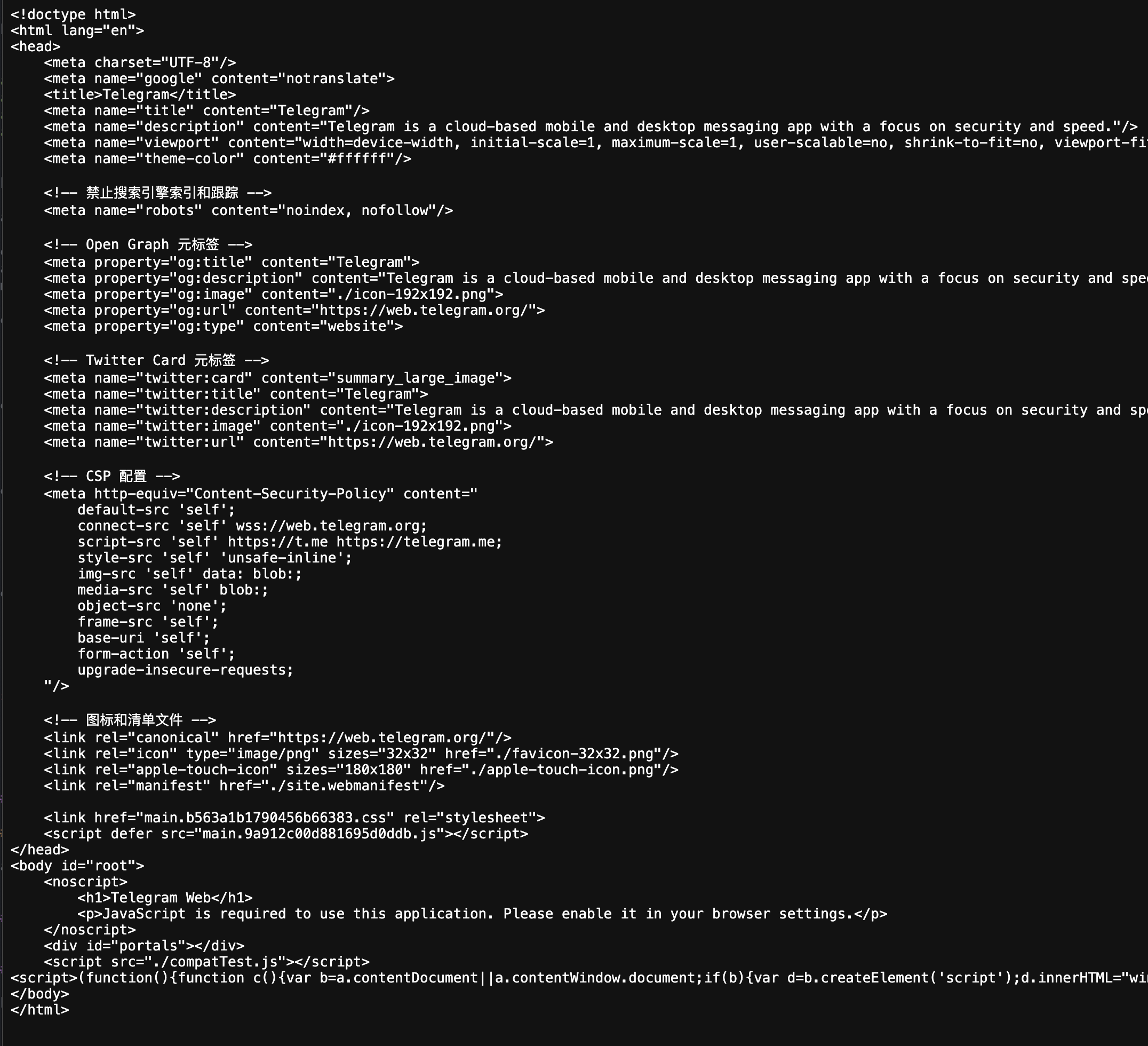
While reviewing the JS, HTML, and CSS, I just skimmed through to get a sense of the scripts being loaded. Nothing complex, but it should give you an idea of what’s supposed to load and what isn’t.
Google Dork
Let’s begin and start with a simple keywords list and Google dorks
Keyword List:
- Telegram
- Please confirm your country code and enter your phone number
- Open Telegram on your phone”
- Log in to Telegram by QR code
These are UILs in the Telegram legit website.
Google Dork:
This dork will list out all the domain
1
2
3
intext:"Please confirm your country code and enter your phone number" -site:*.telegram.org telegram
intext:"Log in to Telegram by QR code" -site:*.telegram.org telegram
intext:"Open Telegram on your phone" -site:*.telegram.org
Sometimes, this comes in handy for checking if any fake websites have already been indexed by Google. You can use the same method for other sites too. I personally use Google Alerts for this. It notifies me whenever a new suspicious site appears. But most of the time the impersonate website will include this
which tell the crawler not to index or display the page on the search result & do not follow any links on the page
As you can see, with just a few searches, we’ve already identified some potential fake websites. However, keep in mind there’s some bias here—not every impersonation site is necessarily malicious.
Most impersonation websites have a short lifespan, so chances are they won’t even get indexed but you should try anyway
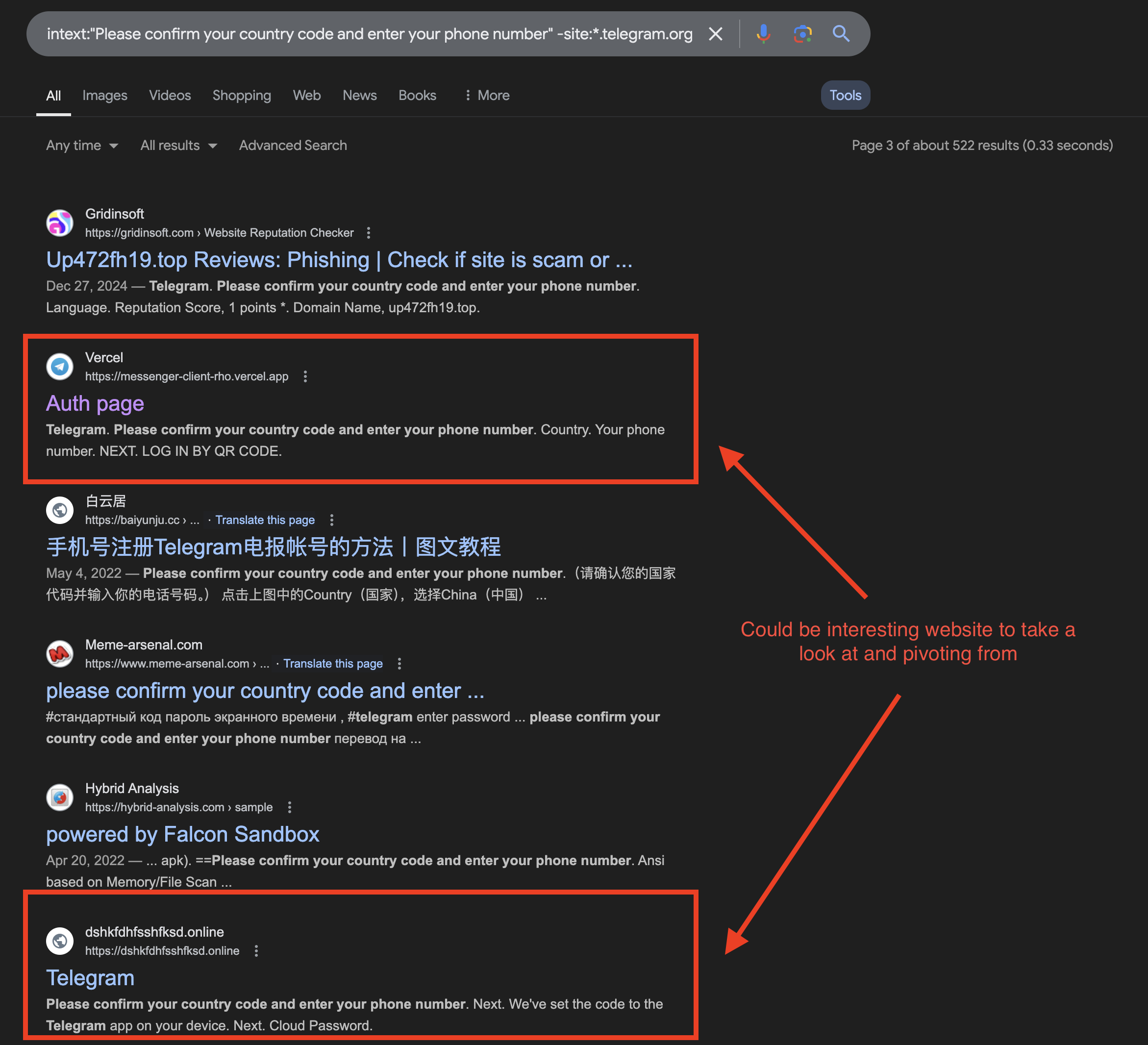
You could manually check each website, or automate the process with Google dorks to crawl and extract content from search results—like interesting JavaScript snippets or unusual HTML structures. Personally, I just pick a random site and use URLScan to see if there are any similar ones.
If you’re unsure whether a domain is legitimate or want to dig deeper, you can look into WHOIS records, inspect the HTML and JavaScript, or use Burp Suite to intercept requests and see if anything suspicious pops up.
You might even consider running a vulnerability scan on the server—it really depends on the situation.
After the dorking phase, you can explore other data sources. In this case, I’ll use URLScan.io along with free, open phishing databases like PhishTank and PhishStats.
2025/02/11 Updated: while noindex and no follow could be use but several search engine probably will ignore it such as Yandex, Bing, or other search engine, so you search using other search engine to find impersonate website
Phish Tank & Phish Stats
By using PhishStat.info API, which you can take a look at it right here: API Documentation by default it will return 20 results, but I’ll but the _size=100
This command will use the api from the phishstats to get some phising site that has reported as impersonate Telegram and we will pivoting from that
1
curl --insecure -XGET -H "Content-type: application/json" 'https://phishstats.info:2096/api/phishing?_where=(title,like,~Telegram~)&_sort=-id&_size=100' | jq
Example output:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
{
"id": 11228739,
"url": "http://www.guzi945.top/",
"ip": "104.21.1.88",
"countrycode": "",
"countryname": "",
"regioncode": "",
"regionname": "",
"city": "",
"zipcode": "",
"latitude": "0.0000",
"longitude": "0.0000",
"asn": "AS13335",
"bgp": "104.16.0.0/12",
"isp": "CLOUDFLARENET, US",
"title": "Telegram",
"date": "2025-01-21T02:29:27.000Z",
"date_update": "2025-01-21T05:39:39.000Z",
"hash": "1482c96533fdc5ce06952c36d55af966218da8919f75e523025f4abec64a559f",
"score": 6.3,
"host": "www.guzi945.top",
"domain": "guzi945.top",
"tld": "top",
"domain_registered_n_days_ago": null,
"screenshot": null,
"abuse_contact": "abuse@guzi945.top",
"ssl_issuer": null,
"ssl_subject": null,
"alexa_rank_host": null,
"alexa_rank_domain": null,
"n_times_seen_ip": 1,
"n_times_seen_host": 1,
"n_times_seen_domain": 1,
"http_code": 403,
"http_server": "cloudflare",
"google_safebrowsing": "No",
"virus_total": "Yes",
"abuse_ch_malware": "No",
"threat_crowd": null,
"threat_crowd_subdomain_count": null,
"threat_crowd_votes": null,
"vulns": null,
"ports": "80, 443, 2082, 2083, 2086, 2087, 2096, 8080, 8443",
"os": null,
"tags": "cdn",
"technology": null,
"page_text": null
}
The website that we found in the phishstats and still active is hxxps://www.guzi945[.]top/
Addtional Information:
- 40 days old
- Created on 2024-12-23
- Expires on 2025-12-23
- Updated on 2025-01-15
- Registrar WHOIS Server: www.gname.com
-> The domain is newly regisistered
Pivoting from information we gathered
The search result from URLScan.io: https://urlscan.io/result/59f0bf0e-a8ea-4d5b-8a16-8edfd8527b36/
URLScan.io search query:
The search query syntax is here.
1
2
3
4
page.url: guzi945.top
page.url: guzi*.top
page.url: *945.top
page.url: guz*.top
These search query aim to find more domain that potential using this techniques call , you can read more about that at here: Mass Telegram account hijacking via supply-chain phishing campaign
Sadly I didn’t find any related domain to this guzi945[.]top
So I will inspect HTML & Javascript that this page loaded, to see if there are any pivoting point we could use. At the time I wrote this, I’don’t have a lot of knowledge about Phishing Kit but I do know that when the Telegram Web is on the Github and the Threat Actor could modify and make their own immpersonate website pretty easy.
Here are some repository for you, you can take a look and understand more about the Telegram Web
Here at the guzi945[.]top I’ve checked all the javascript that loaded by the website as such:
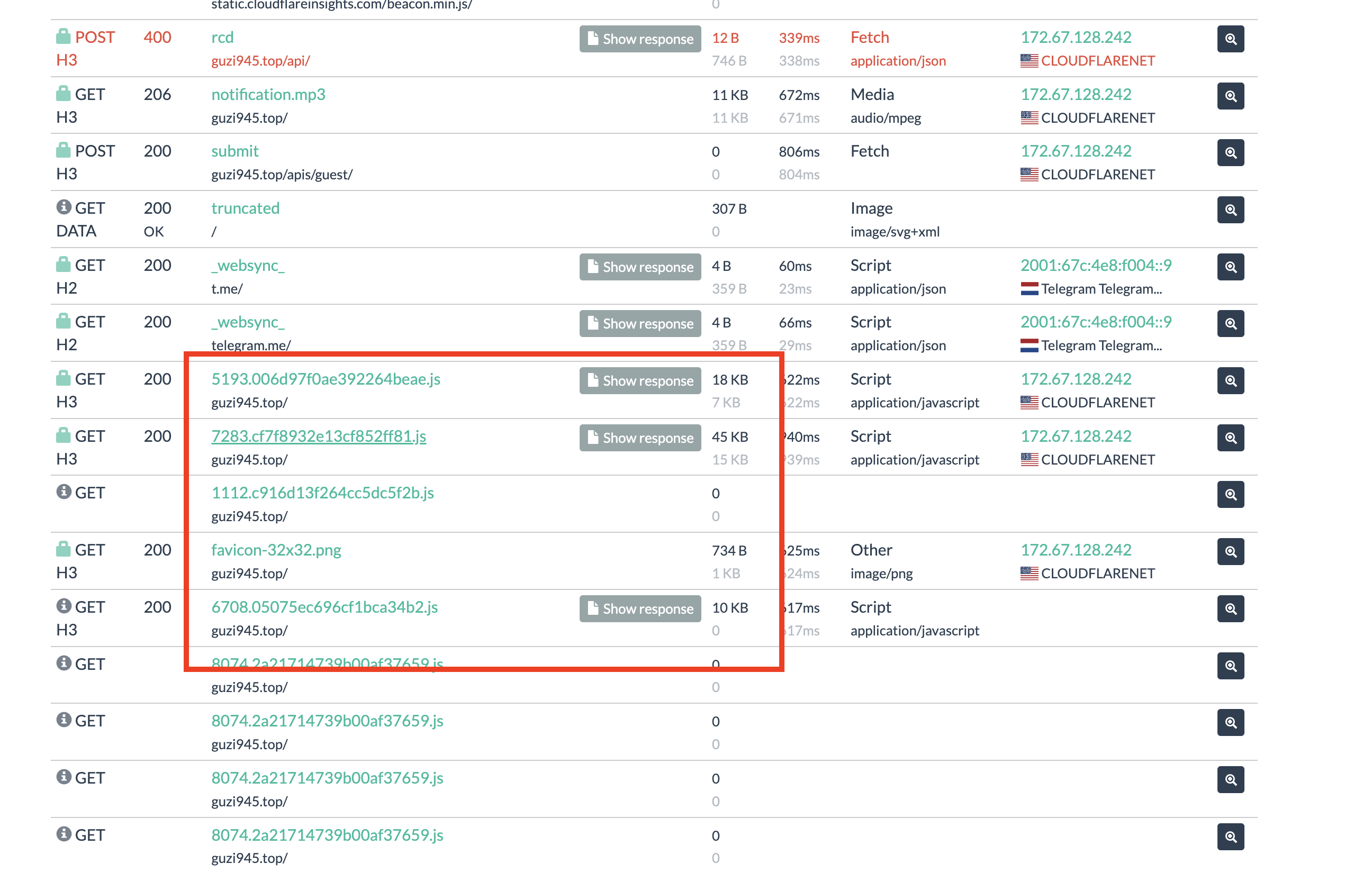
Here is the URLScan.io query: (Pivoting on filename)
1
filename:"6708.05075ec696cf1bca34b2.js"
We use the name of javascript that loaded to pivot more impersonate Telegram Login page, here is the result of the URLScan, which probably 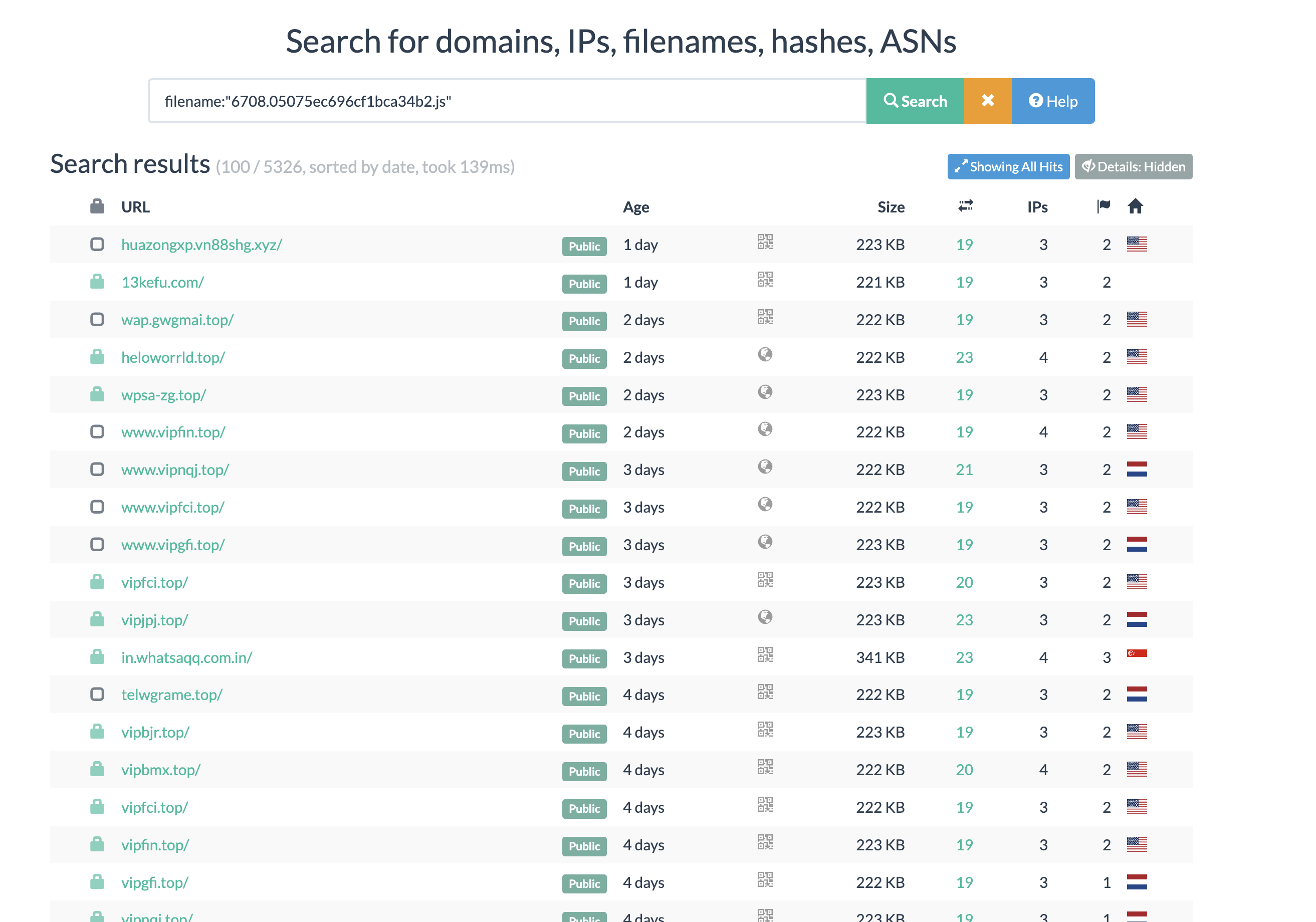
Also I try to use Censys, the query is for any HTML Title has Telegram and a response body that has the chinese words like this (Pivoting on HTML content)
1
(services.http.response.html_tags="<title>Telegram</title>") and services.http.response.body="*禁止搜索引擎*"
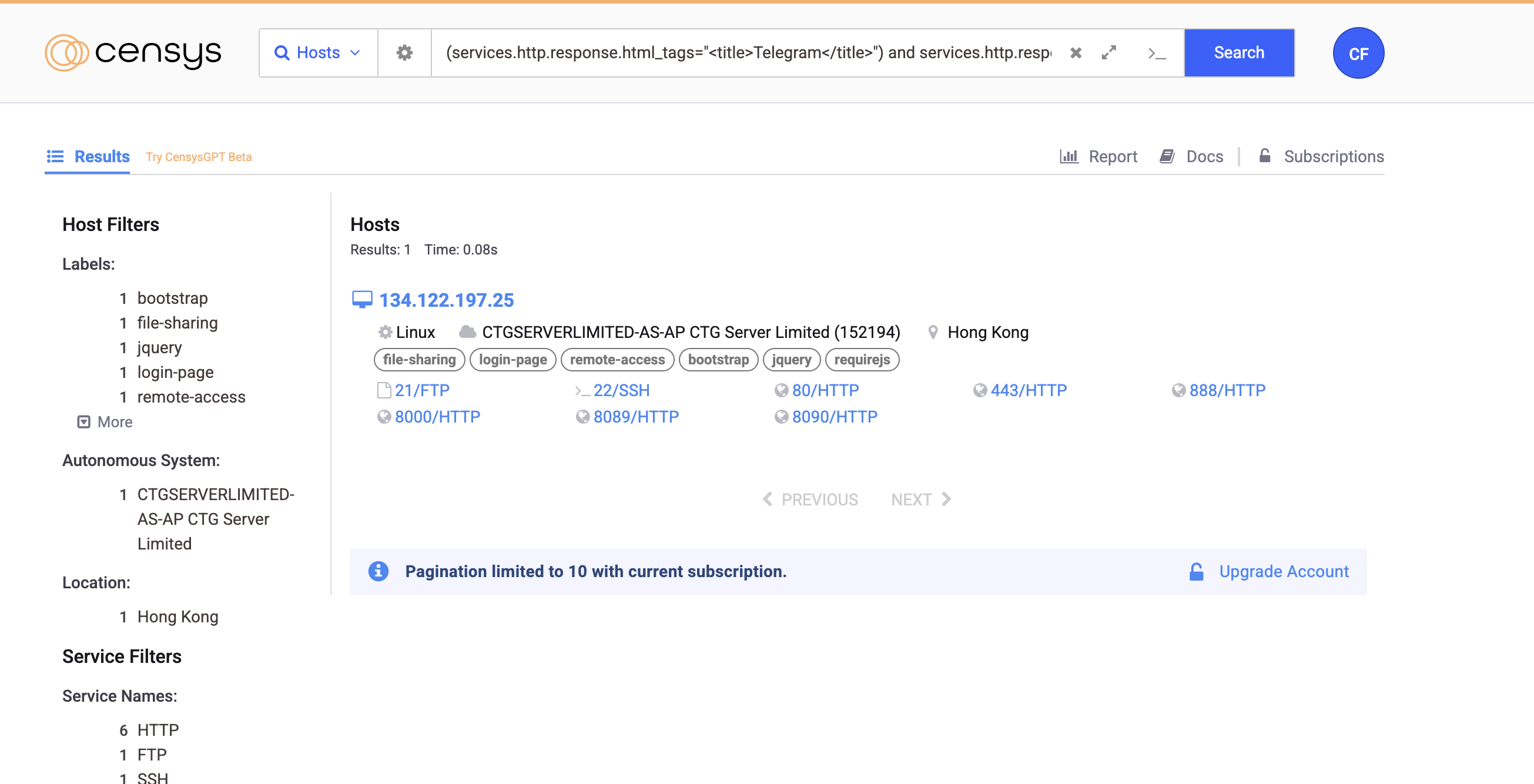
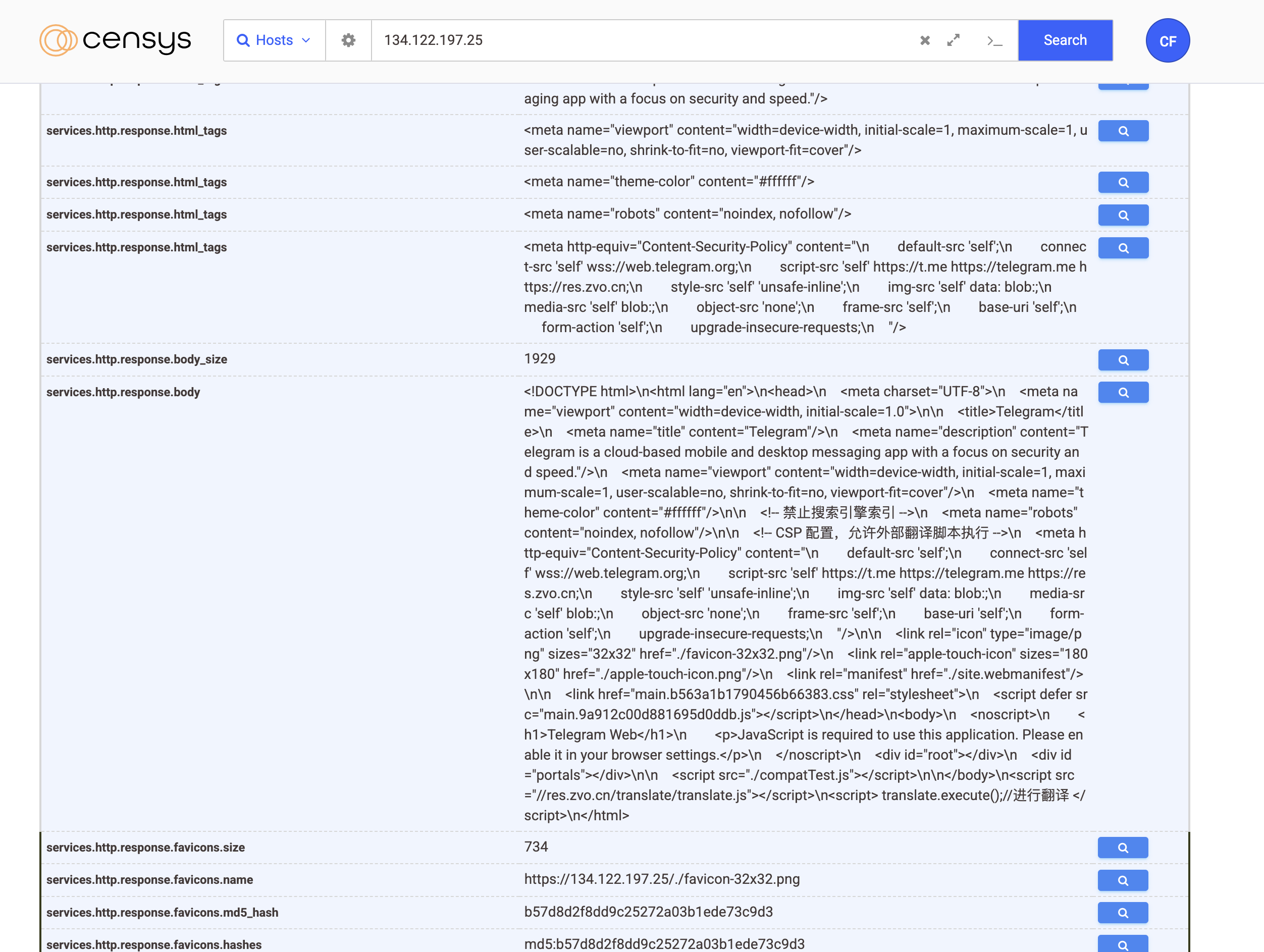 {: w=”600” h=”200” }
{: w=”600” h=”200” }
It is not the same page (guzi945[.]top) but this is a small connection because well it has the same chinese HTML comments. Which we could use to pivot to others website
Chinese comments
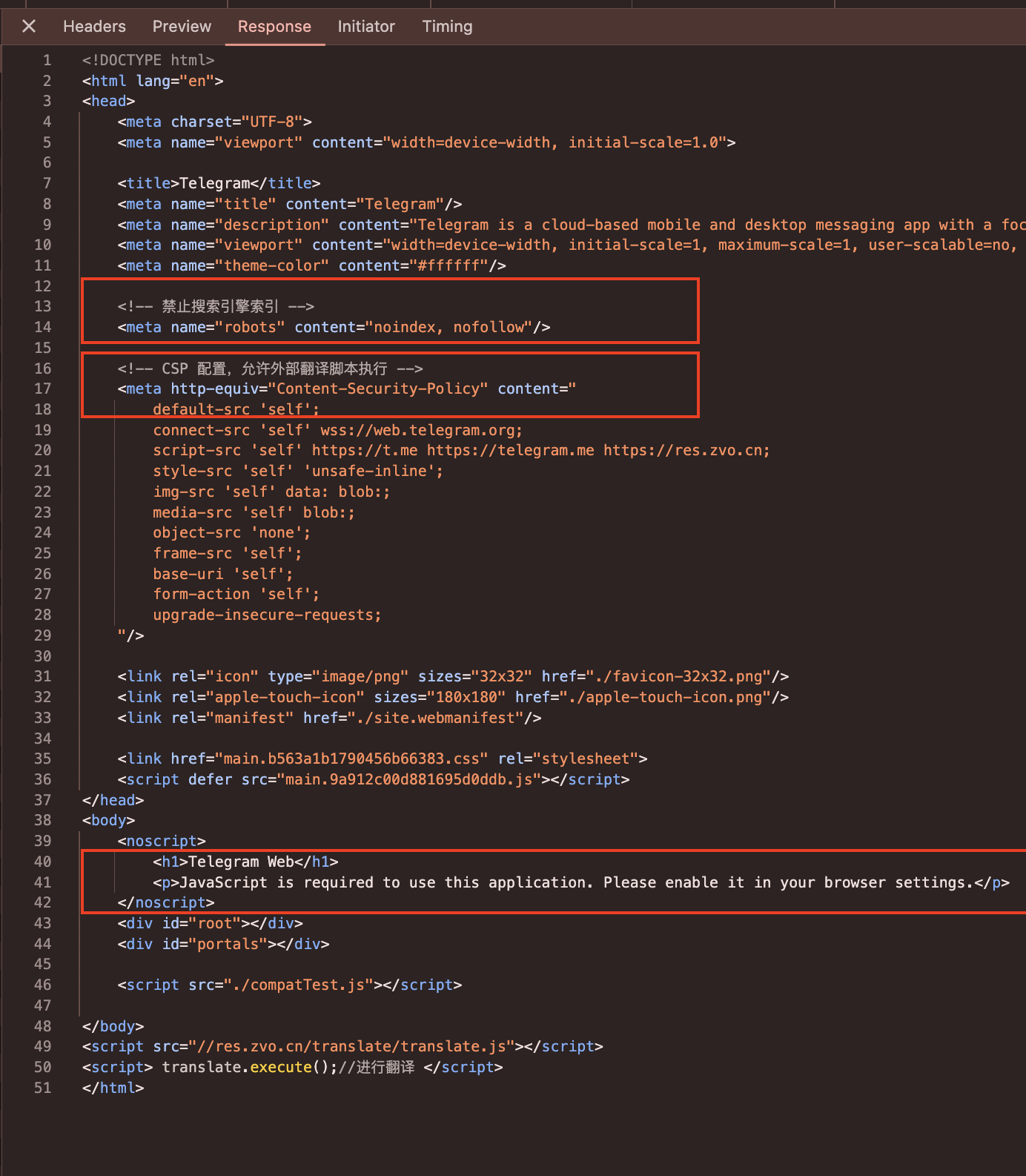
The results:
- IP Address: 134.122.197.25
- Country: Hong Kong (HK)
- CN: biepie.pro
- Cert Fingeprint: Here
There is a bias to consider here: the JavaScript file name might simply be a file generated by a phishing kit. This phishing kit could be used by multiple threat actors, or the file might even originate from legitimate Telegram source code. Therefore, the presence of the same file name alone is not strong evidence linking it to the same threat actor. In this case, based on the observation and the script content, I can hypothesize that these impersonation websites were generated using the same phishing kit.
Pivoting on anything you can, you can either pivoting from file name, hash of the file, name of domain, certificate, and many more. to find more information.
-> As you can see we will go down a rabbit hole real quick, During the writing of this blog, I plan to have a another blog about how to find the Threat Actor behind the impersonate website if possible.
Conclusion and my bias and gap
How I find impersonate website:
- By leveraing existing or opensource phishing information
- By taking a look at the legit website & the impersonate website to find pivoting point
- By using tools such as Censys, Shodan, URLScan - internet scanner I would say, in order to find these website
The techniques (or just how I do it) to find impersonate website is still a cases by cases. I know that there are plenty of phishing kit, most of them will leave a footprint which you can analyze and create a pivoting method in order to find them all.
Conclusion
- Find any Impersonate Telegram Login Page -> Yes
- Check if those website belong to a mass phishing campain or not -> Hmm not quite so
- Find the person behind the impersonate website if possible -> We didn’t found it or attemp to find it :))
Biases & Gap
- Gap is that I don’t have the pool of realtime phishing alert or any type of scanner or newly registered domains & not have a extensive knowledge about many phishing kit
- Gap is that I didn’t create any mindmap to correlatd those finding
- Should have make an action, if the impersonate website isn’t reporting -> should be able to report & pubish on MISP or twitter about new finding.
- Does not find out the true entity behind it
Refs for Hunting Impersonate Website or Phishing
These are the article that I read in order to obtain this knowledge also inspired by it and in the end create this blog, to show case the action that I took upon this information.